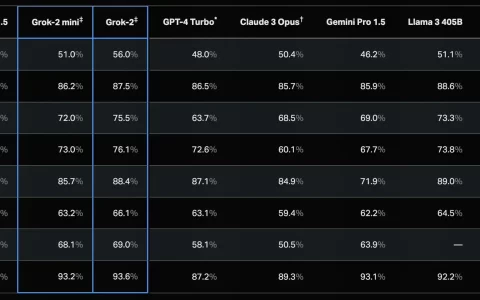
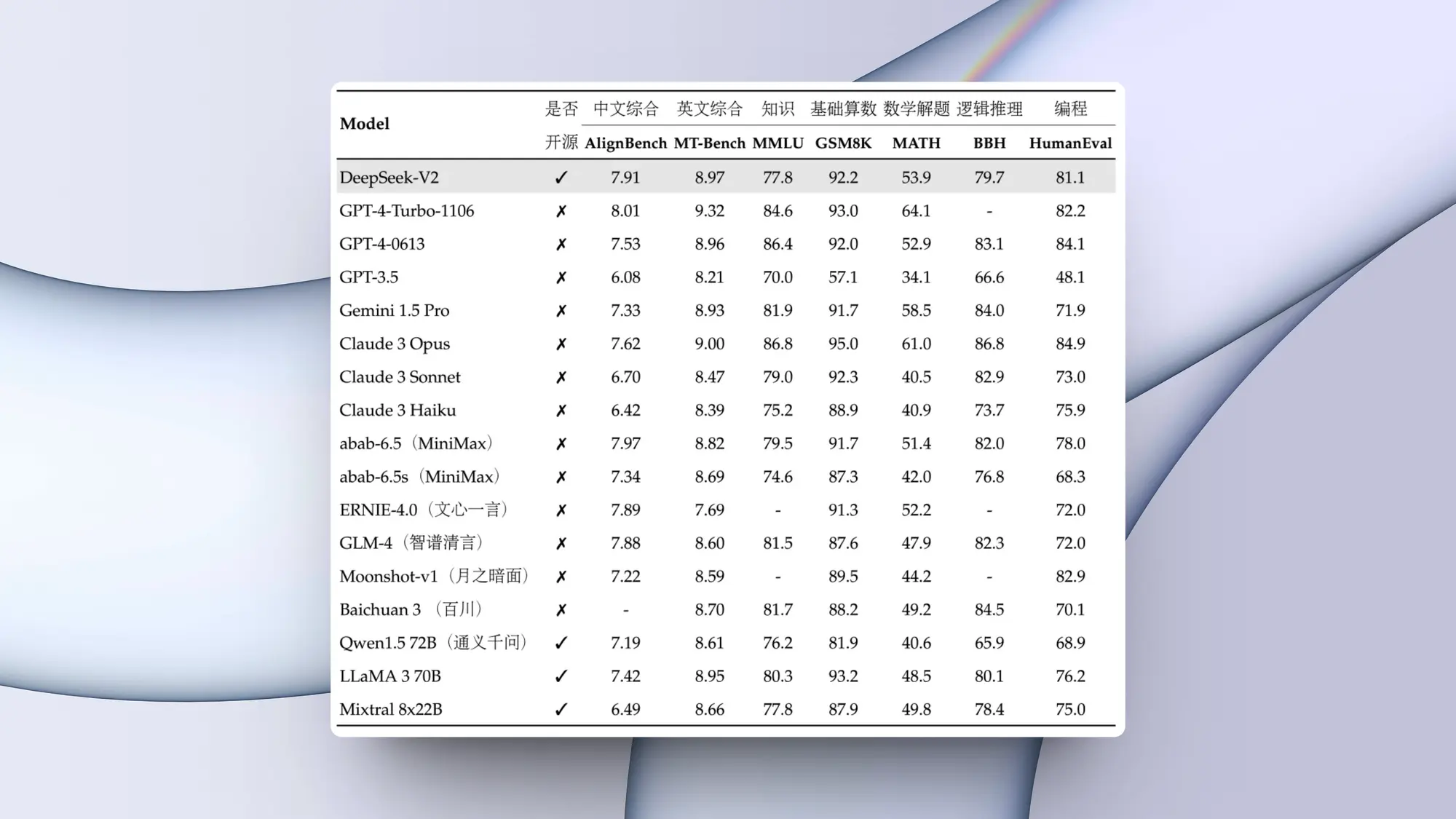
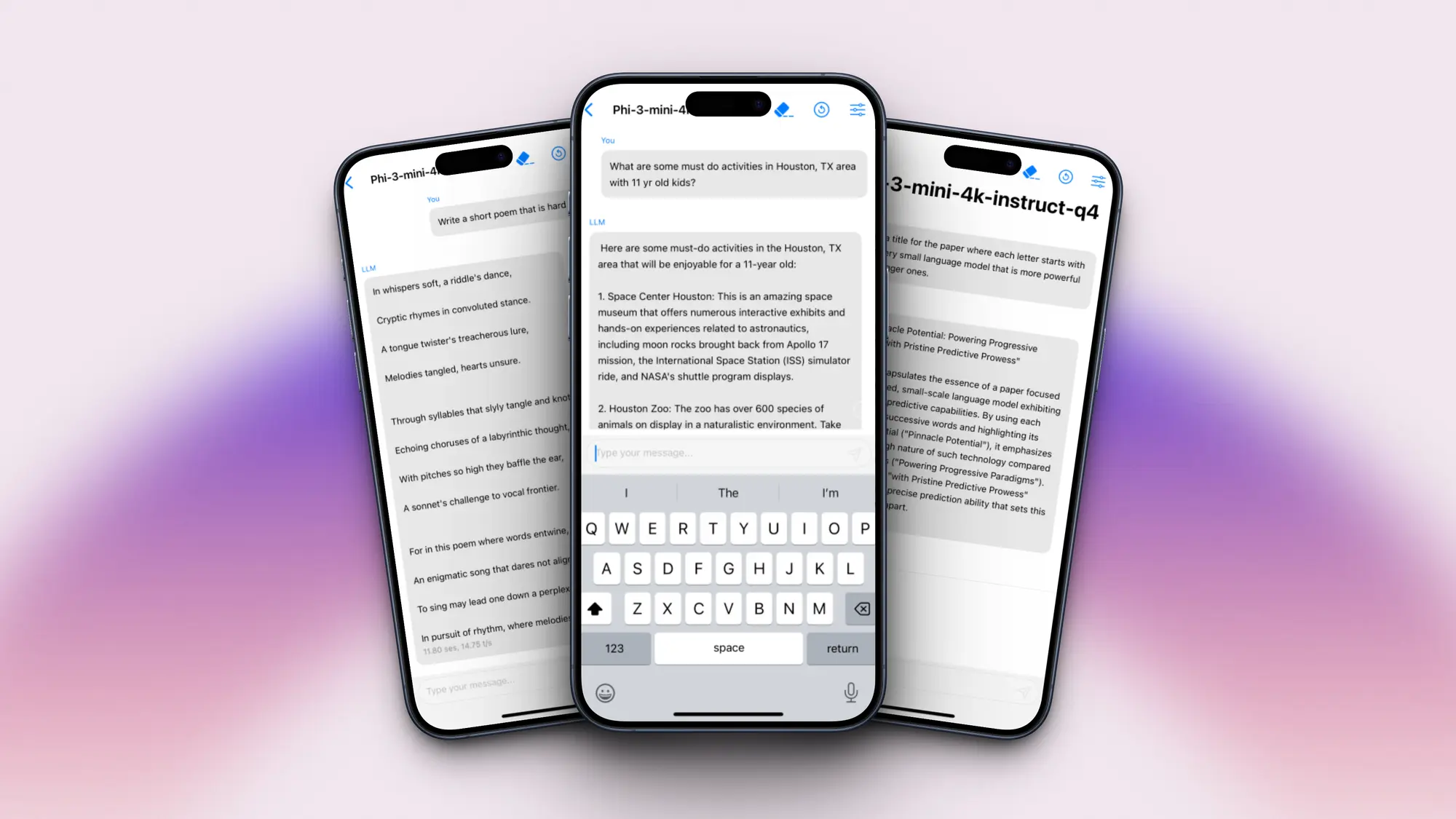
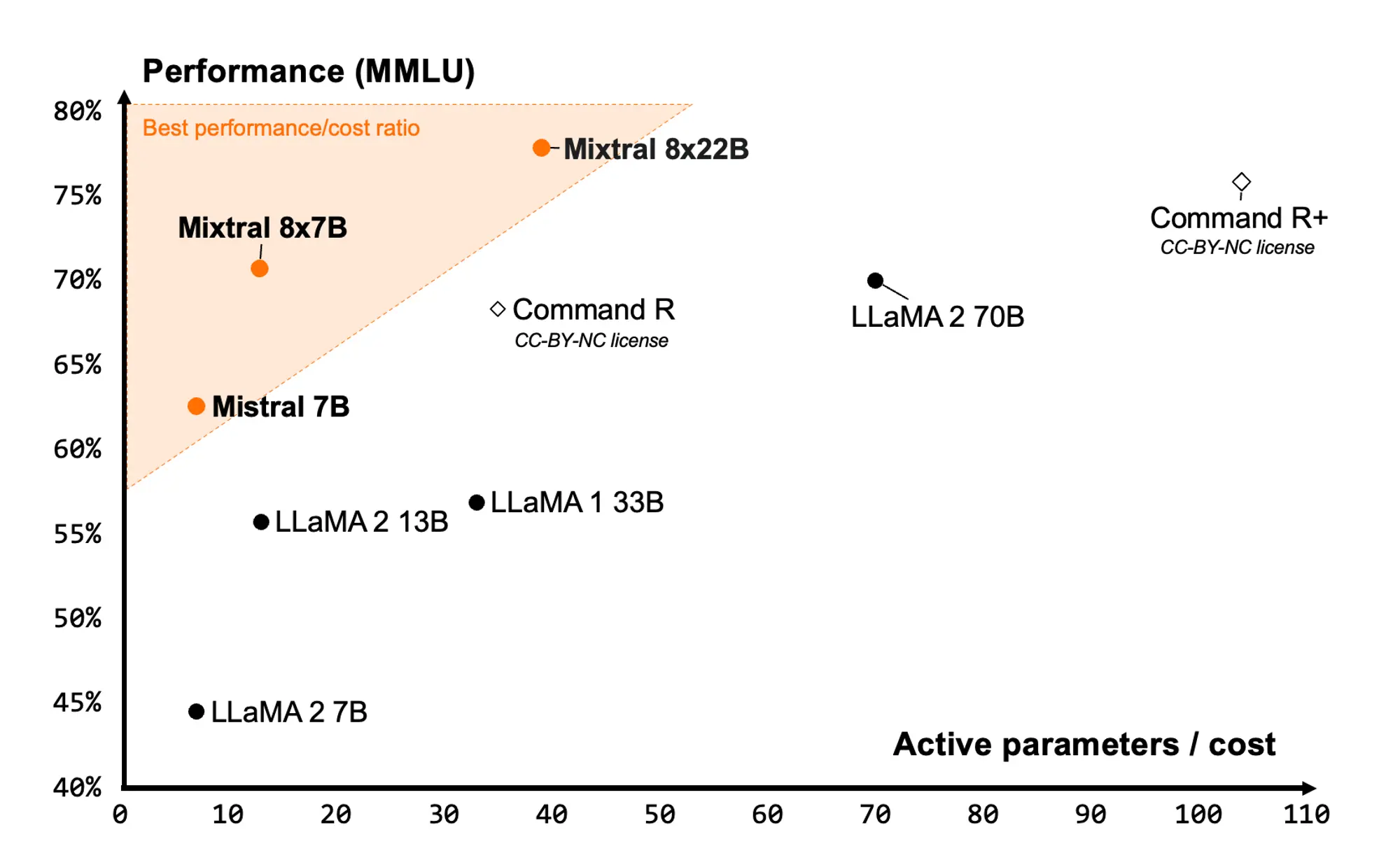
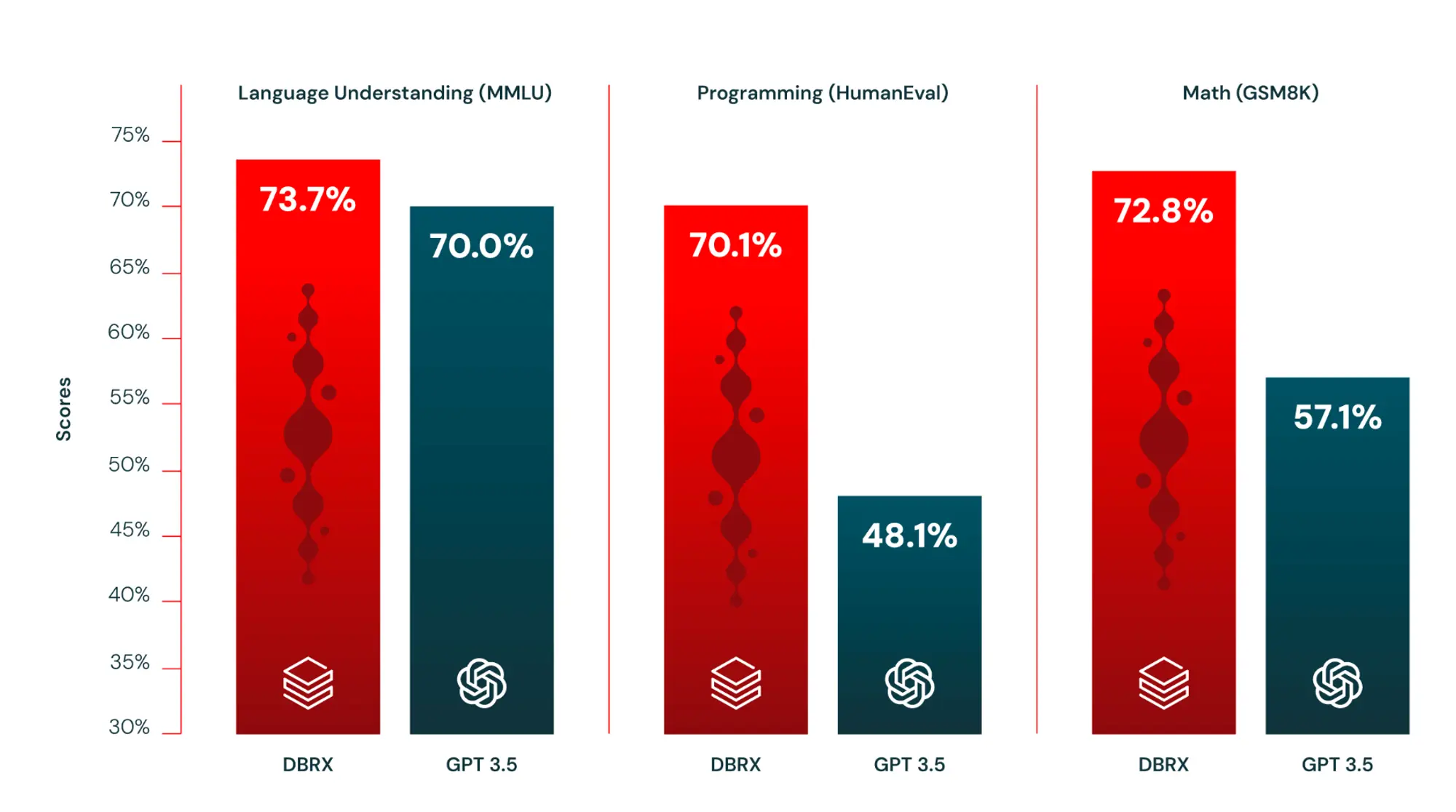
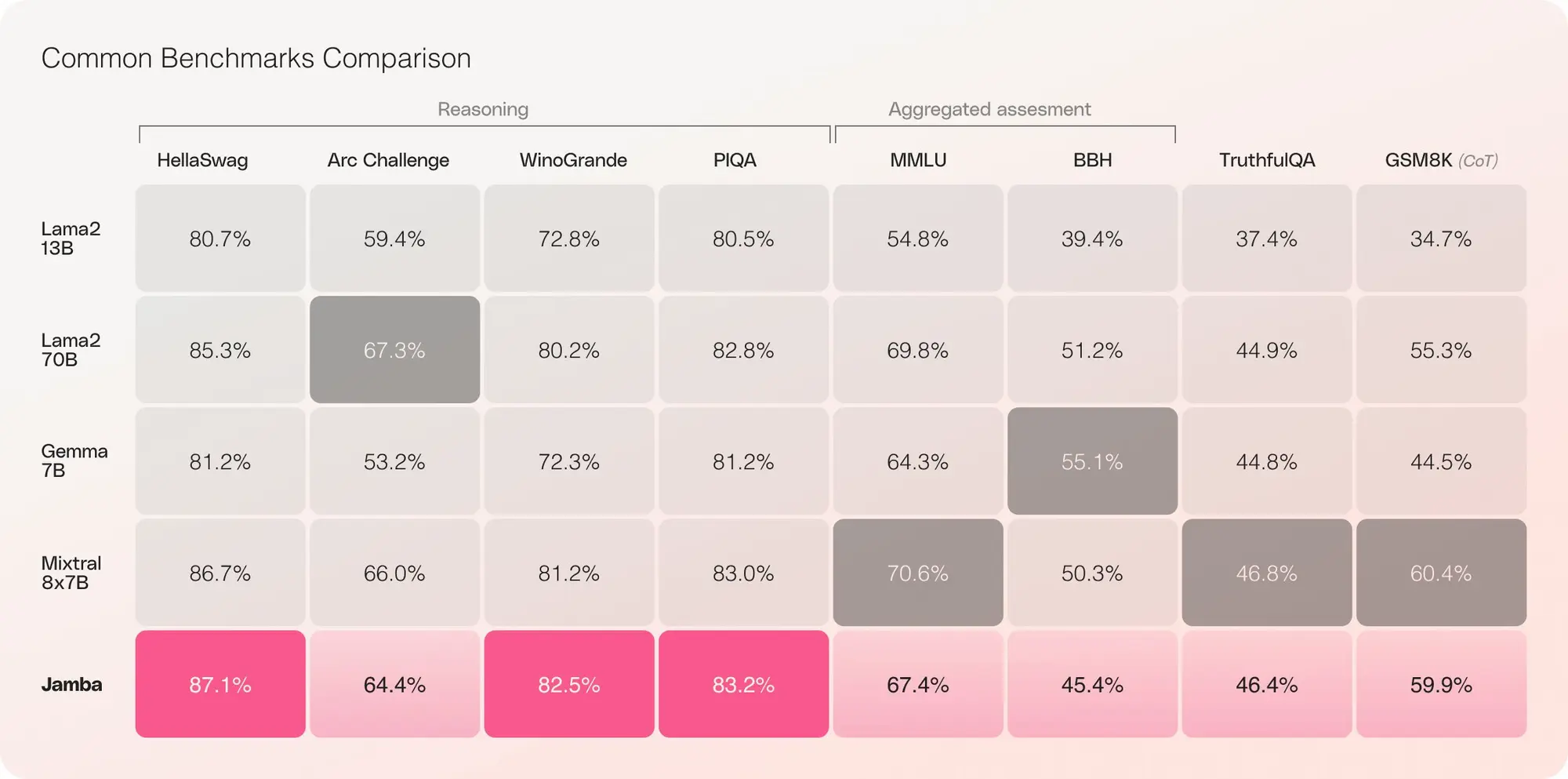
高质量合成数据的重要性再一次被证明。
open ai 的逻辑是使用一个足够庞大且非常不经济的推理模型(strawberry)生产优质合成数据帮助训练下一个阶段的普适模型(猎户座)。
同时逸散的部分合成数据顺便用来微调和蒸馏上一代模型 gpt-4,确保上一代模型的持续微小进步(gpt-4o)。
据 the information 报道,openai 可能会在今年秋天发布strawberry的chatgpt版本。
strawberry 这个模型的推理能力相较于现在的模型大幅加强,可以真正实现将思考时间转化为输出质量,它的增强逻辑应该能更有效地解决与语言相关的挑战。
sam 也说他们已经邀请美国国家安全部门开始测试他们的先进模型。
另外还有一个规划中的代号 “orion(猎户座)“旗舰语言模型,旨在超越 gpt-4。strawberry 将通过为 orion 生成数据来做出贡献。strawberry 和高质量合成数据的结合可能会减少 orion 中的错误。
strawberry可能用了跟斯坦福的方法。又重新看了一下这个论文,quiet-star 通过三个步骤提高模型推理能力:
并行生成理由:首先,在输入序列的每个标记位置并行生成多个理由。每个理由的长度为t,并在每个理由的开始和结束处插入学习的起始和结束标记。
混合后理由和基础预测:然后,使用一个混合头从每个理由的隐藏状态输出和原始文本标记的隐藏状态输出中生成一个权重,该权重决定了在后续标记预测中使用多少后理由的预测逻辑。
优化理由生成:最后,使用reinforce算法优化理由生成参数,以增加使未来文本更可能的理由的可能性。
原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/yun299485.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重