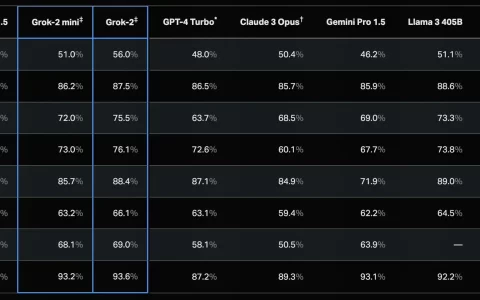
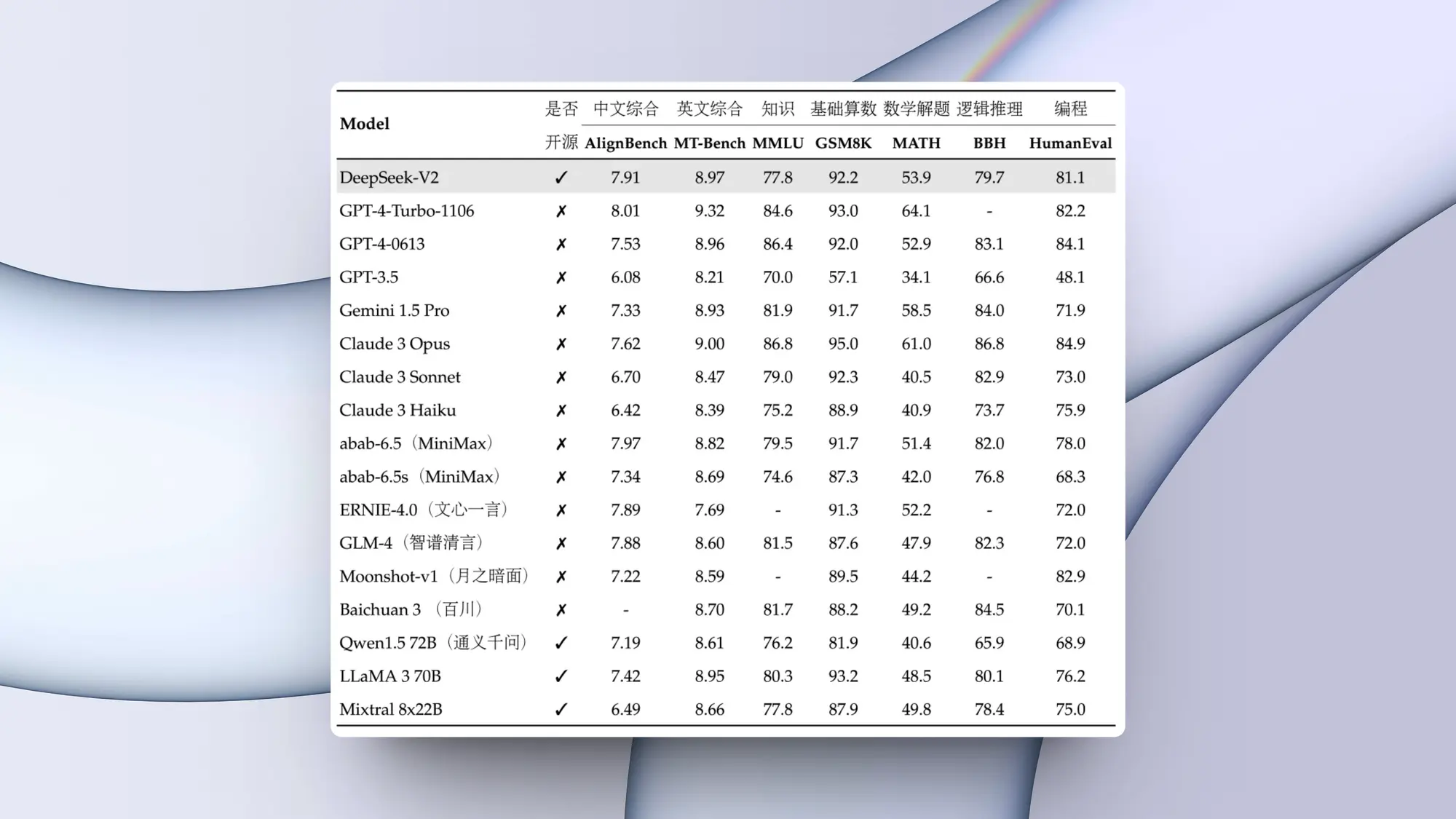
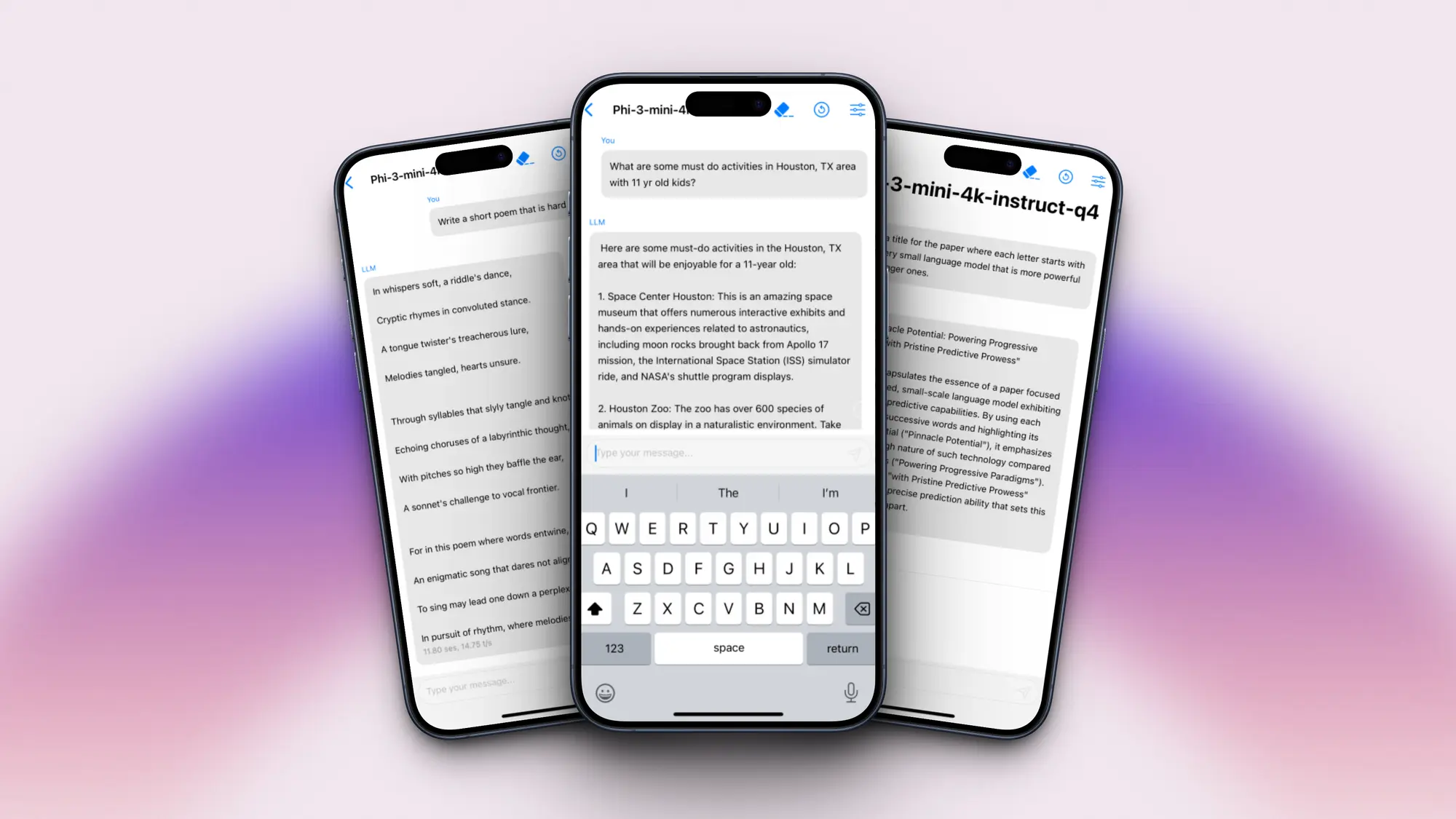
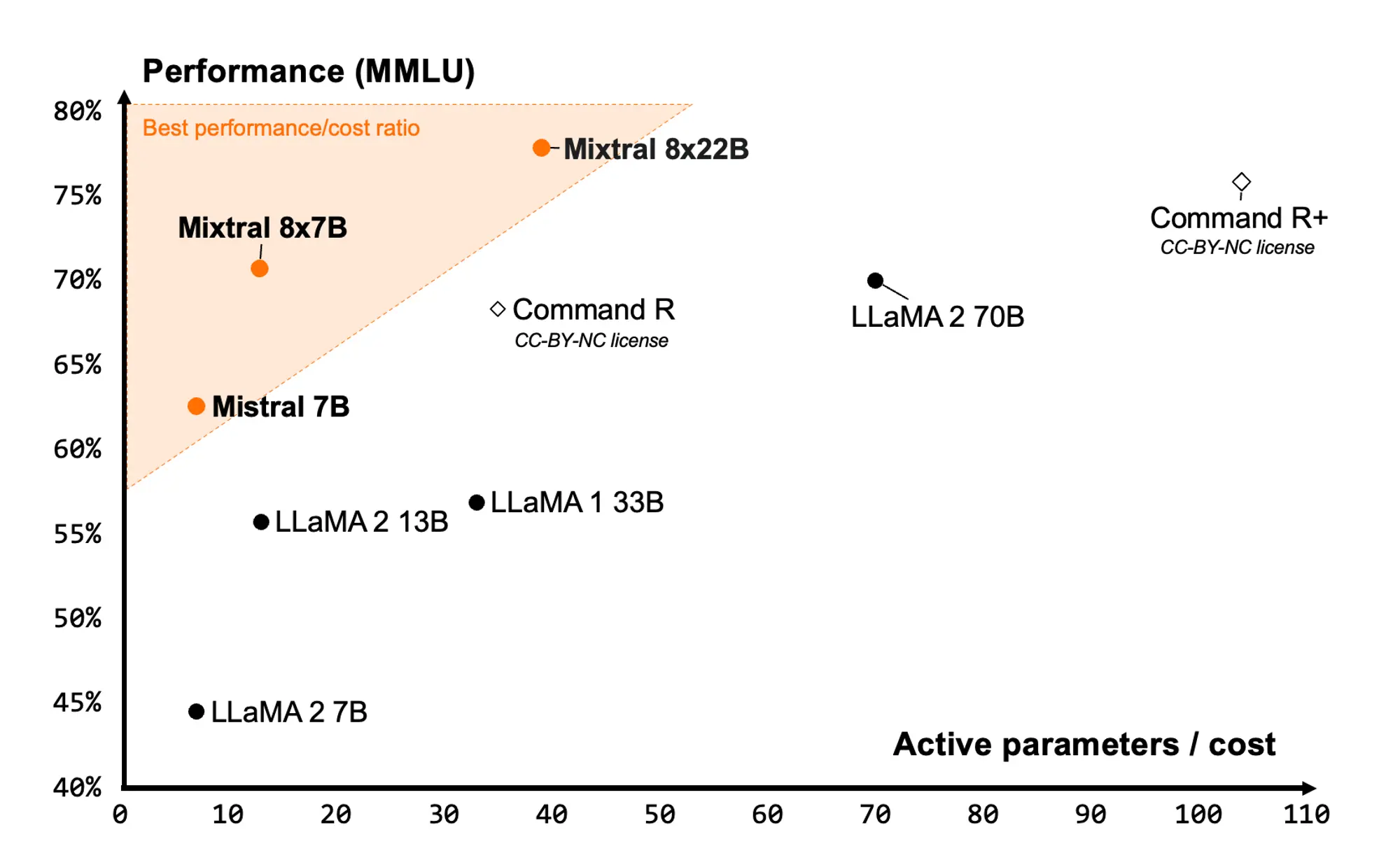
magic 发布了一个具有 1 亿 token 上下文的模型 ltm-2-mini。1 亿 token相当于大约 1000 万行代码或大约 750 本小说。
- ltm 模型不依赖于模糊的记忆,而是能够在推理时处理高达 100m token 的上下文信息。
- 现有的长上下文评估方法存在隐含的语义提示,这降低了评估的难度,使得 rnn 和 ssm 等模型能够得到好的评分。
- magic 团队提出了 hashhop 评估方法,通过使用哈希对,要求模型存储和检索最大可能的信息量,从而提高了评估的准确性。
- ltm-2-mini 模型在处理超长上下文时,其序列维度算法的成本远低于 llama 3.1 405b 模型的注意力机制。
原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/yun299482.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重