模型架构:
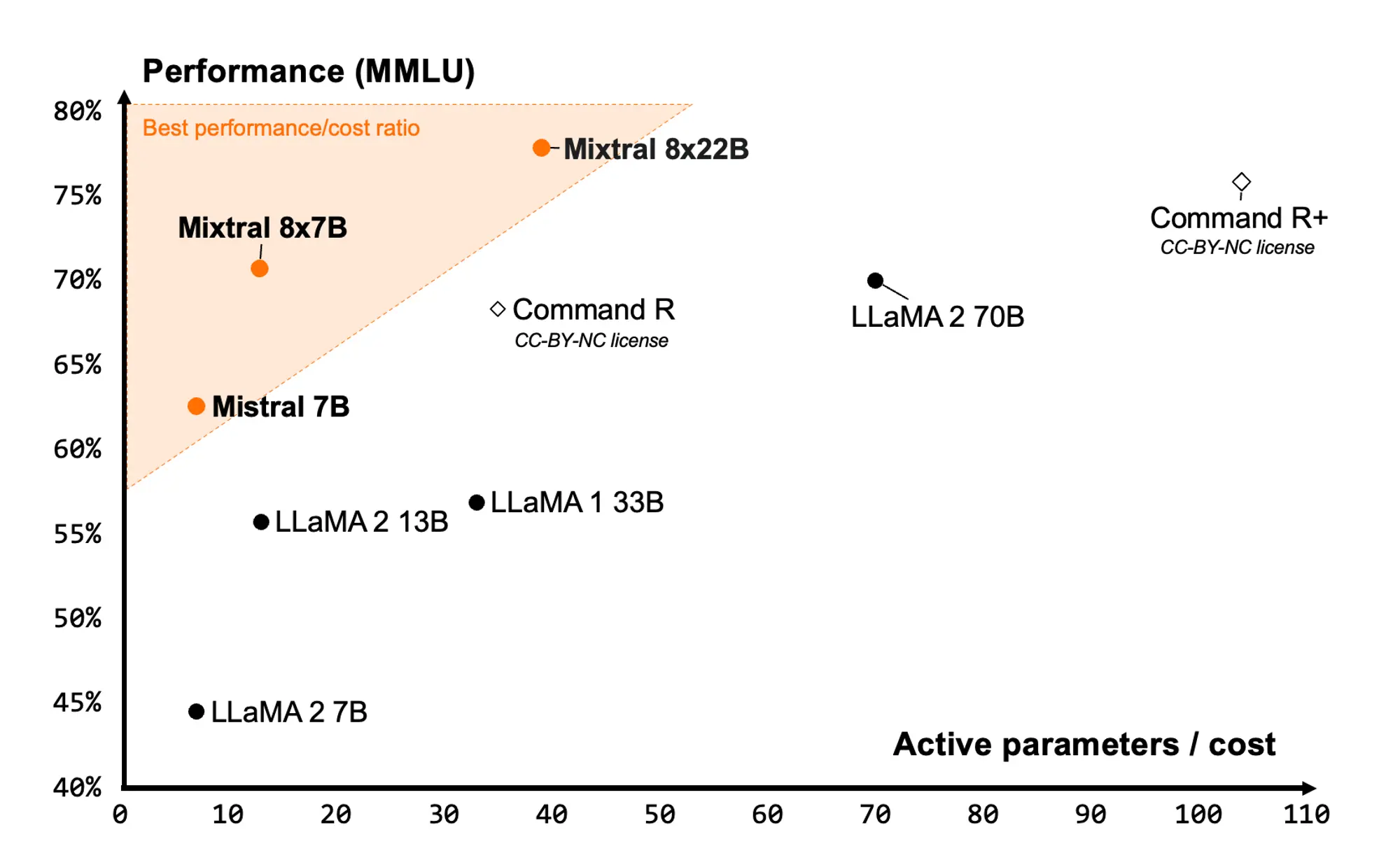
132b参数的moe模型,一共拥有16个专家,每个token激活4个专家,意味着有36b的活跃参数,mixtral只有13b的活跃参数(少了近3倍)。
性能表现 :
它在语言理解、编程、数学和逻辑方面轻松击败了开源模型,如 llama2-70b、mixtral 和 grok-1
dbrx 在大多数基准测试中超过了 gpt-3.5。
dbrx 是基于 megablocks 研究和开源项目构建的专家混合模型(moe),使得该模型在每秒处理的标记数量方面非常快速。
数据训练:
以12万亿token的文本和代码进行预训练,支持的最大上下文长度为32k tokens。

原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/yun295716.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重